C++基础知识复习
基础复习
基础知识
\1. 指针和引用的区别
- 指针是一个变量,存储一个地址,大小为 4(32位)、8(64位)字节,可以有多级指针,指针可以初始化为空,可以被多次改变,sizeof(指针)得到指针的大小,指针作为参数传递的时候有一个形参向函数栈帧拷贝数据的过程,拷贝的是一个固定字节的地址变量, 4 或 8 字节。(相当于传递地址值)
- 引用原变量的别名,与原变量实际是同一个东西,只能有一级,初始化时不能为null,必须初始化为另一具体的变量,初始化后不能再改变。sizeof(引用)得到引用所指向的变量大小。
\2. 区别指针类型
int\* p[10]
int (\*p)[10]
int \*p(int)
int (\*p)(int)- **int *p[10]**表示指针的数组,强调数组概念,是一个数组变量,数组大小为10,其元素都是指针类型。
- **int (*p)[10]**表示数组的指针,强调是一个指向数组的指针,只有一个变量,是指针类型,不过指向的是一个int类型的数组,这个数组大小是10。
- **int *p(int)**是函数声明,函数名是p,参数是int类型的,返回值是int *类型的。
- **int (*p)(int)**是函数指针,强调是指针,该指针指向的函数具有int类型参数,并且返回值是int类型的
\3. 值传递、指针传递、引用传递的区别和效率
- **值传递:**有一个形参向函数所属的栈拷贝数据的过程,如果值传递的对象是类对象,或是大的结构体对象,将耗费一定的时间和空间。(传值)
- **指针传递:**同样有一个形参向函数所属的栈拷贝数据的过程,但拷贝的数据是一个固定为4字节的地址。 (传值,传递的是地址值)
- **引用传递:**同样有上述的数据拷贝过程,但其是针对地址的,相当于为该数据所在的地址起了一个别名。(传地址)
- 效率上讲,指针传递和引用传递比值传递效率高。一般主张使用引用传递,代码逻辑上更加紧凑、清晰,指针传递的话要解引用。
- 引用必须在声明时初始化,不能为空,这就避免了空指针的问题。
- 引用一旦绑定到一个对象,就不能再重新绑定到其他对象,这提高了代码的稳定性。
\4. 堆和栈的区别
- 申请方式不同:栈由系统自动分配,堆需要手动申请和释放
- 申请大小限制不同:栈顶和栈底是提前预设好的,栈是高地址向底地址拓展,可以通过ulimit-a查看,ulimit-s修改。
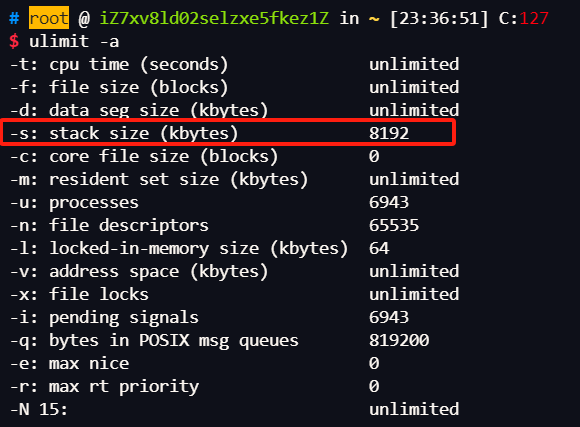
- 申请效率不同:
- 栈由系统分配,速度快,不会有碎片。
- 堆由程序员分配,速度慢,且会有碎片。
\5. new 和 delete 如何实现
- new的实现过程是:
- 分配内存:new 操作符首先调用内存分配函数(通常是 malloc 或者操作系统提供的其他内存分配函数)来分配足够的内存,以容纳所需的对象。
- 调用构造函数:在内存分配成功后,new 操作符会在分配的内存上调用对象的构造函数,以初始化对象。
- 返回指针:最终,new 操作符返回一个指向新分配和初始化对象的指针。
- delete的实现过程:
- 调用析构函数:delete 操作符首先调用对象的析构函数,以清理对象占用的资源。
- 释放内存:在析构函数调用完成后,delete 操作符会调用内存释放函数(通常是 free)来释放之前分配的内存。
\6. malloc申请的内存能用delete释放吗
不能,因为不安全)
new和delete会自动进行检查其类型和大小,而malloc/free不能执行构造函数和析构函数,所以动态对象它是不行的。
但是理论上malloc的内存可以被delete释放,但是不要这么写。
#include <iostream>
#include <cstdlib>
class MyClass {
public:
MyClass() {
std::cout << "Constructor called" << std::endl;
}
~MyClass() {
std::cout << "Destructor called" << std::endl;
}
void sayHello() {
std::cout << "Hello from MyClass" << std::endl;
}
};
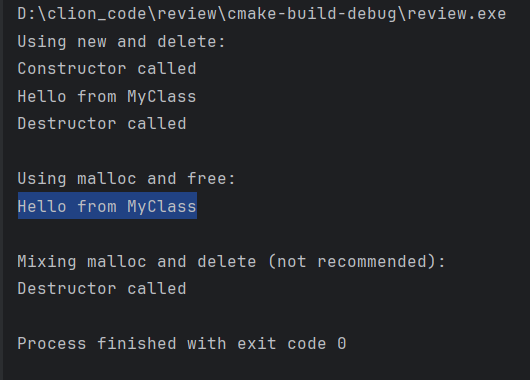
int main() {
// 使用 new 和 delete
std::cout << "Using new and delete:" << std::endl;
MyClass\* obj1 = new MyClass();
obj1->sayHello();
delete obj1;
std::cout << "\nUsing malloc and free:" << std::endl;
// 使用 malloc 和 free
MyClass\* obj2 = (MyClass\*)malloc(sizeof(MyClass));
// 注意:这里不会调用构造函数
obj2->sayHello(); // 这可能导致未定义行为
free(obj2); // 这里不会调用析构函数
std::cout << "\nMixing malloc and delete (not recommended):" << std::endl;
// 混合使用 malloc 和 delete (不推荐)
MyClass\* obj3 = (MyClass\*)malloc(sizeof(MyClass));
delete obj3; // 这可能导致未定义行为
return 0;
}
\7. 宏定义和函数的区别
- 宏在预处理阶段完成替换,之后被替换的文本参与编译,相当于直接插入了代码,运行时不存在函数调用,执行起来更快; 函数调用在运行时需要跳转到具体调用函数。
- 宏定义属于在结构中插入代码,没有返回值;函数调用具有返回值,
- 宏定义参数没有类型,不进行类型检查; 函数参数具有类型,需要检查类型,
- 宏定义不要在最后加分号。
#include <iostream>
#include <chrono>
// 宏定义
#define SQUARE(x) ((x) \* (x))
// 函数定义
int square(int x) {
return x \* x;
}
// 用于测量执行时间的宏
#define MEASURE\_TIME(func) \
do { \
auto start = std::chrono::high\_resolution\_clock::now(); \
func; \
auto end = std::chrono::high\_resolution\_clock::now(); \
std::chrono::duration<double, std::milli> elapsed = end - start; \
std::cout << #func << " took " << elapsed.count() << " ms\n"; \
} while(0)
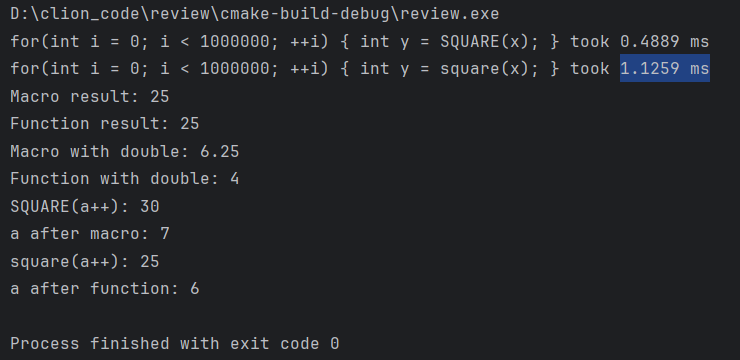
int main() {
int x = 5;
// 1. 执行速度比较
MEASURE\_TIME(for(int i = 0; i < 1000000; ++i) { int y = SQUARE(x); });
MEASURE\_TIME(for(int i = 0; i < 1000000; ++i) { int y = square(x); });
// 2. 返回值
// 宏没有返回值,直接插入代码
int macro\_result = SQUARE(x);
// 函数有返回值
int func\_result = square(x);
std::cout << "Macro result: " << macro\_result << std::endl;
std::cout << "Function result: " << func\_result << std::endl;
// 3. 类型检查
double d = 2.5;
// 宏不进行类型检查
std::cout << "Macro with double: " << SQUARE(d) << std::endl;
// 函数会进行类型检查(这里会有隐式类型转换)
std::cout << "Function with double: " << square(d) << std::endl;
// 4. 宏的潜在问题
int a = 5;
std::cout << "SQUARE(a++): " << SQUARE(a++) << std::endl;
std::cout << "a after macro: " << a << std::endl;
a = 5;
std::cout << "square(a++): " << square(a++) << std::endl;
std::cout << "a after function: " << a << std::endl;
return 0;
}
\8. 函数传参时,什么时候用指针 or 引用
- 需要返回函数内局部变量的内存的时候用指针。使用指针传参需要开辟内存,用完要记得释放指针,不然会内存泄漏。而返回局部变量的引用是没有意义的
- 对栈空间大小比较敏感(比如递归)的时候使用引用。使用引用传递不需要创建临时变量,开销要更小
- 类对象作为参数传递的时候使用引用,这是C++类对象传递的标准方式
\9. 宏定义和 typedef 的区别
- 宏 主要用于定义常量及书写复杂的内容。宏替换发生在编译阶段之前,属于文本插入替换。宏不检查类型,宏不是语句,不在最后加分号;
- typedef 主要用于定义类型别名,typedef是编译的一部分。typedef 会检查数据类型,typedef是语句,要加分号标识结束。
- 注意对指针的操作,typedef char* p_char和#define p_char char*区别巨大。
\10. Sizeof 和 strlen 的区别
因为sizeof值在编译时确定,所以不能用来得到动态分配(运行时分配)存储空间的大小。
- sizeof 是运算符,并不是函数,结果在编译时得到而非运行中获得;sizeof参数可以是任何数据的类型或者数据
- strlen是字符处理的库函数。strlen的参数只能是字符指针且结尾是"\0'的字符串。
\11. 怎么判断两个浮点数相等
浮点数不能用 == 判断。
方法:
- 自定义精度 EPS: abs(a - b) < ESP
if ( !( a > b || b > a )) 如果浮点数a、b不想等,那么 !(xxx || xxx ) 一定是 (! 1) == 0
\12. C++的内存分区
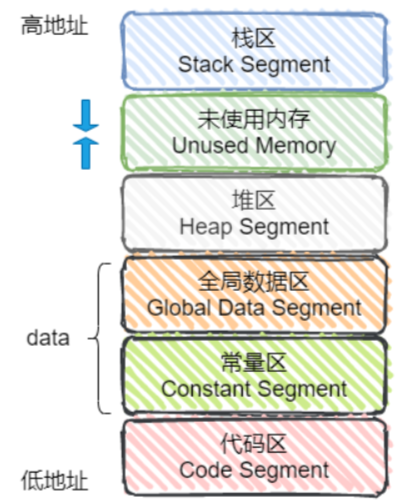
\13. 初始化和赋值的区别
- 对于简单类型来说,初始化和赋值没什么区别
- 对于类和复杂数据类型来说,这两者的区别就大了。
\14. Extern "C" 的用法
在程序中加上extern "C"后,相当于告诉编译器这部分代码是C语言写的,因此要按照C语言进行编译,而不是C++;
(1)C++调用C函数:
//xx.h
extern int add(...)
//xx.c
int add(){
}
//xx.cpp
extern "C" {
#include "xx.h"
}(2)C调用C++函数
//xx.h
extern "C"{
int add();
}
//xx.cpp
int add(){
}
//xx.c
extern int add();\15. 野指针和悬空指针
- 野指针:指针变量未及时初始化 => 定义指针变量及时初始化,要么置空。
- 悬空指针:指针free或delete之后没有及时置空 => 释放操作后立即置空
避免野指针比较简单,但悬空指针比较麻烦。c++引入了智能指针,C++智能指针的本质就是避免悬空指针的产生。
\16. 浅拷贝和深拷贝
浅拷贝
浅拷贝只是拷贝一个指针,并没有新开辟一个地址,拷贝的指针和原来的指针指向同一块地址,如果原来的指针所指向的资源释放了,那么再释放浅拷贝的指针的资源就会出现错误。
深拷贝
深拷贝不仅拷贝值,还开辟出一块新的空间用来存放新的值,即使原先的对象被析构掉,释放内存了也不会影响到深拷贝得到的值。
在自己实现拷贝赋值的时候,如果有指针变量的话是需要自己实现深拷贝的。
#include <iostream>
#include <string.h>
using namespace std;
class Student
{
private:
int num;
char \*name;
public:
Student(){
name = new char(20);
cout << "Student" << endl;
};
~Student(){
cout << "~Student " << &name << endl;
delete name;
name = NULL;
};
Student(const Student &s){//拷贝构造函数
//浅拷贝,当对象的name和传入对象的name指向相同的地址
name = s.name;
//深拷贝
//name = new char(20);
//memcpy(name, s.name, strlen(s.name));
cout << "copy Student" << endl;
};
};
int main()
{
{// 花括号让s1和s2变成局部对象,方便测试
Student s1;
Student s2(s1);// 复制对象
}
system("pause");
return 0;
}
//浅拷贝执行结果:
//Student
//copy Student
//~Student 0x7fffed0c3ec0
//~Student 0x7fffed0c3ed0
//\*\*\* Error in /tmp/815453382/a.out': double free or corruption (fasttop): 0x0000000001c82c20 \*\*\*
//深拷贝执行结果:
//Student
//copy Student
//~Student 0x7fffebca9fb0
//~Student 0x7fffebca9fc0\17. 智能指针(c++11)
\1. shared_ptr
采用引用计数器的方法,允许多个智能指针指向同一个对象,每当多一个指针指向该对象时,指向该对象的所有智能指针内部的引用计数加1,每当减少一个智能指针指向对象时,引用计数会减1,当计数为0的时候会自动的释放动态分配的资源。
\2. unique_ptr
unique_ptr采用独享所有权语义,一个非空的unique_ptr始终拥有其指向的资源。
转移一个unique_ptr时,所有权会从源指针完全转移到目标指针,源指针会被置空。因此,unique_ptr不支持普通的拷贝和赋值操作,无法直接用于STL标准容器中,除非是局部变量的返回值(因为编译器知道返回的对象即将被销毁)。
如果尝试拷贝一个unique_ptr,会导致两个指针指向同一资源,从而在销毁时对同一内存进行多次释放,导致程序崩溃。
\3. weak_ptr
weak_ptr(弱引用)用于解决引用计数中的环形引用问题。环形引用会导致相互引用的内存无法释放。为了解决这一问题,引入了weak_ptr,它是一种不影响对象生命周期的智能指针,专门用于配合shared_ptr使用。
weak_ptr指向由shared_ptr管理的对象,但不增加引用计数。即使有weak_ptr引用该对象,当所有shared_ptr被销毁后,内存仍会被释放。因此,weak_ptr不保证其指向的内存一定有效。在使用weak_ptr之前,应该调用lock()函数来检查它是否为空指针。
\4. 智能指针的循环引用
环引用是指使用多个智能指针share_ptr时,出现了指针之间相互指向,从而形成环的情况,有点类似于死锁的情况,这种情况下,智能指针往往不能正常调用对象的析构函数,从而造成内存泄漏。
弱指针用于专门解决shared_ptr循环引用的问题,weak_ptr不会修改引用计数,即其存在与否并不影响对象的引用计数器。
\5. 手写实现智能指针需要哪些函数
一个构造函数、拷贝构造函数、复制构造函数、析构函数、移动函数
智能指针是一个数据类型,一般用模板实现,模拟指针行为的同时还提供自动垃圾回收机制。
它会自动记录SmartPointer<T*>对象的引用计数,一旦T类型对象的引用计数为0,就释放该对象。
除了指针对象外,我们还需要一个引用计数的指针设定对象的值,并将引用计数计为1,需要一个构造函数。新增对象还需要一个构造函数,析构函数负责引用计数减少和释放内存。
通过覆写赋值运算符,才能将一个旧的智能指针赋值给另一个指针,同时旧的引用计数减1,新的引用计数加1
\18. ++i 和 i++ 哪个好
- ++i 返回一个引用,
- i++ 返回一个对象值,并在过程中产生临时对象,导致效率降低
\19. 内存对齐以及原因
- 分配内存的顺序是按照声明的顺序。
- 每个变量相对于起始位置的偏移量必须是该变量类型大小的整数倍,不是整数倍空出内存,直到偏移量是整数倍为止。
- 最后整个结构体的大小必须是里面变量类型最大值的整数倍。
类
\1. 重载、重写、隐藏的区别
重载 Overload
- 重载和函数成员是否是虚函数无关。
- 特点是函数名相同,参数类型和数目有所不同。
- 不能出现参数个数和类型均相同,仅仅依靠返回值不同来区分的函数。
class A{
...
virtual int fun();
void fun(int);
void fun(double, double);
static int fun(char);
...
}重写 Override
- 派生类中覆盖基类中的同名函数。
- 重写就是重写函数体,要求基类函数必须是虚函数
//父类
class A{
public:
virtual int fun(int a){}
}
//子类
class B : public A{
public:
//重写,一般加override可以确保是重写父类的函数
virtual int fun(int a) override{}
}隐藏 hide
派生类中的函数屏蔽了基类中的同名函数,包括以下情况:
- 两个函数参数相同,但是基类函数不是虚函数。和重写的区别在于基类函数是否是虚函数
- 两个函数参数不同,无论基类函数是不是虚函数,都会被隐藏。和重载的区别在于两个函数不在同一个类中。
\2. 虚函数和纯虚函数
- **虚函数:**virtual return_type function_name(parameters) { /* 可以有实现 */ }
- 定义一个函数为虚函数,不代表函数为不被实现的函数。
- 定义他为虚函数是为了允许用基类的指针来调用子类的这个函数。
- **纯虚函数:**virtual return_type function_name(parameters) = 0;
- 定义一个函数为纯虚函数,才代表函数没有被实现。
- 定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。
\3. 面向对象的三大特性
继承
- **定义:**让某种类型对象获得另一个类型对象的属性和方法。
- 实现方式:
- 实现继承:指使用基类的属性和方法而无需额外编码的能力
- 接口继承:指仅使用属性和方法的名称、但是子类必须提供实现的能力
封装
- **定义:**将数据和代码捆绑在一起避免外界干扰和不确定性访问。把客观事物封装成抽象类,用访问修饰符划分访问权限。
多态
- **定义:**同一事物变现出不同事物的能力
- **实现方式:**多态性通常通过继承和虚函数来实现。重载(实现编译时多态)、重写(实现运行时多态)
\4. Const 和 static 、volatile 的作用
- const 用于定义不可变的常量。
- static 控制变量或函数的生命周期和作用域。
- volatile 告诉编译器不要优化这个变量,因为它可能在程序的其他部分或外部环境中被改变。
const关键字
- 常量定义:可以定义不可更改的常量,比如const int PI = 3.14;。
- 指针和引用:可以创建指向常量的指针或引用,以及常量指针或引用。
- const int* ptr指针所指向的整数是常量,不能通过这个指针修改它所指向的整数,但指针本身是可以修改的。
- int* const ptr指针本身是常量,初始化后不能修改它所指向的地址,但可以通过这个指针修改它所指向的整数。
- 函数参数和返回值:可以在函数参数和返回值前加上const,以表明这些参数和返回值在函数内部不能被修改。
- 成员函数:在成员函数声明前加上const关键字,表示该成员函数不会修改该类的任何成员变量。这对于类的接口设计非常重要,因为可以让使用者清楚地知道哪些成员函数是安全的,不会导致数据的改变。
static关键字
- 全局变量:可以使全局变量具有内部链接性,即该变量只能在定义它的文件中访问。
- 局部静态变量:可以使局部变量在函数调用结束后仍然保留其值,即具有静态存储持续性。
- 静态成员变量:定义类中的静态成员变量,表示这个变量是所有对象共享的,而不是每个对象独立的。
- 静态成员函数:定义类中的静态成员函数,这个函数属于类,而不是类的任何特定对象。静态成员函数没有this指针,因此无法访问非静态成员变量和函数。
\5. Final
- 用于类: 防止该类被继承
- 用于虚函数: 防止该虚函数在子类中被重写
\6. 有几种构造函数
- 无参构造函数
- 有参构造函数
- 拷贝构造函数
- .......
析构函数 ~