Go内存逃逸
2024年11月27日
本文详细介绍Go语言中内存逃逸的场景及优化方法。
Go语言内存逃逸的场景
1. 逃逸是什么
编译器用于决定变量分配到堆上还是栈上的一种行为
1.1 发生逃逸的时机
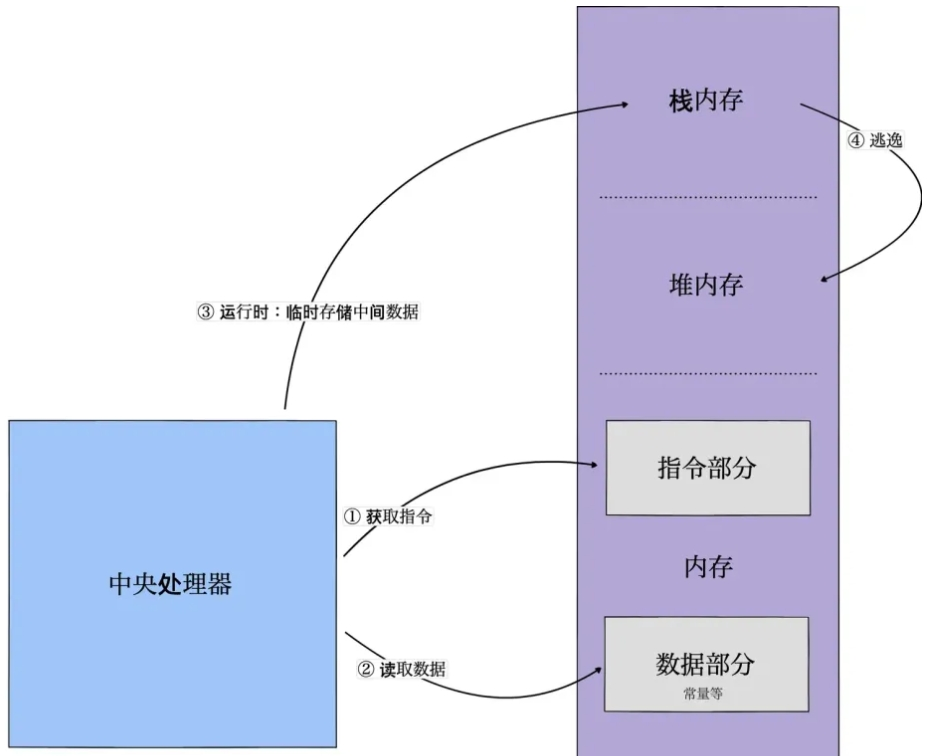
- **首先:**函数运行在栈上,在栈里声明临时变量分配内存, 函数运行完毕后回收内存。每个函数的栈空间都是独立的,其他函数不能进行访问。
- **发生内存逃逸:**在某些情况下,栈上的数据需要在函数结束之后还能被访问,这时会发生内存逃逸:
- 如果变量从栈上逃逸,会跑到堆上:
- 栈上面的变量在函数结束的时候会自动回收,回收代价比较小。而且栈内存的分配和释放,只需要两个CPU指令
PUSH和RELEASE。 - 堆分配内存,需要先找到一块大小合适的内存,之后通过GC回收才能释放,如果频繁进行,占用比较大的系统开销
- 栈上面的变量在函数结束的时候会自动回收,回收代价比较小。而且栈内存的分配和释放,只需要两个CPU指令
- **所以:**尽量在栈上分配内存,可以减少gc压力,提高程序运行速度
2. 逃逸过程
- 如果函数外部没有引用,则优先放到栈中;
- 如果函数外部存在引用,则必定放到堆中;
2.1 基本逃逸分析原则
- 如果一个函数返回了一个变量的引用,那它系一定发生逃逸,逃到堆上。
- 编译器会分析代码的特征和生命周期,Go的变量如果能在编译器编译过程中证明确认在函数返回后不会再被引用,才会分配到栈上。其他情况都是分配到堆上。
- Go中没有一个关键字或者函数可以让变量被编译器分配到堆上,只能是编译器来分析代码确定
3. 逃逸情景
- **指针逃逸:**在函数内部返回一个局部变量指针
- **分配大对象:**导致栈空间不足,不得不分配到堆上
- **调用接口类型的方法:**接口类型的方法调用是动态调度(实际使用的具体实现只能在运行时确定)。
- 尽管在能符合分配到栈的场景,但是它的大小不能在编译时确定的情况,也会分配到堆上
3.1 指针逃逸
- 传递指针可以减少底层值拷贝,提高效率。
- 但是如果拷贝的数据量小,由于指针传递会逃逸(发生了函数外引用),可能会使用到堆,这样子会增加GC的负担,所以传递指针不一定是高效的
- 使用命令:
go build -gcflags '-m' xxx.go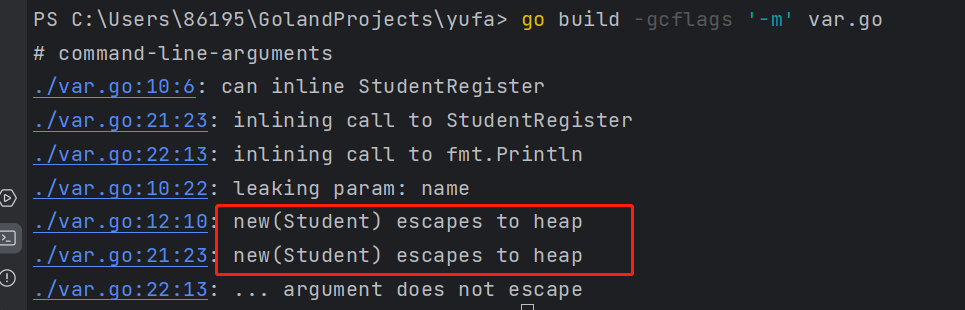
示例代码
package main
import "fmt"
type Student struct {
Name string
Age int
}
func StudentRegister(name string, age int) *Student {
// s 原本是局部指针变量,被返回了引用,逃逸到了堆
s := new(Student)
s.Age = age
s.Name = name
return s
}
func main() {
ss := StudentRegister("kryiea", 20)
fmt.Println(ss)
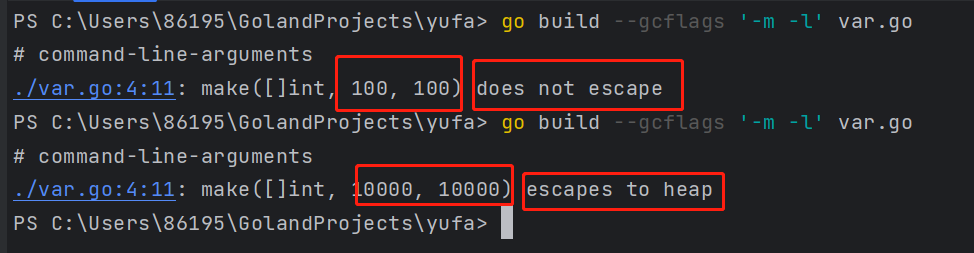
}3.2 栈空间不足逃逸
栈空间足够时,没有逃逸
package main
func MakeSlice() {
s := make([]int, 100, 100)
for index, _ := range s {
s[index] = index
}
}
func main() {
MakeSlice()
}容量增大后,发生逃逸
package main
func MakeSlice() {
s := make([]int, 10000, 10000)
for index, _ := range s {
s[index] = index
}
}
func main() {
MakeSlice()
}
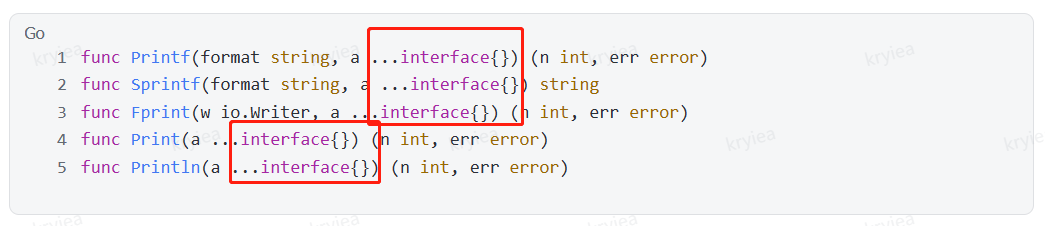
3.3 动态类型逃逸
函数参数为interface,在编译期间很难确定参数具体类型,也能产生逃逸:
3.4 变量大小不确定
在创建切片的时候,初始化切片容量的时候,传入一个变量来指定其大小,由于变量的值不能在编译器确定,所以就不能确定其内存大小,会将对象分配在堆上
package main
func MakeSlice() {
length := 1
a := make([]int, length, length)
for i := 0; i < length; i++ {
a[i] = i
}
}
func main() {
MakeSlice()
}4. 避免逃逸
- 对于性能要求高且访问频次高的函数调用,应该尽量避免使用接口类型。因为go中接口类型的方法调用都是动态,不能再编译阶段确定
- 避免变量大小不能确定的时候
5. 总结
- 不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。
- 但其实当参数为变量自身的时候,复制是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。