Kafka 高可用
2024年1月1日
Kafka 高可用
本文详细介绍了Kafka的副本机制、高可用架构及数据同步原理,帮助读者深入理解Kafka的容灾能力。
一、Kafka 的副本机制
Kafka 是天然提供容灾解决方案的,通过多副本机制来实现容灾。
1. Kafka 副本的概念
- Replica: Replica是指Kafka集群中的一个副本,它可以是Leader的副本或者Follower的副本的一种。每个分区都有多个副本,其中一个是Leader的副本,其余的是Follower的副本。每个副本都保存了分区的完整数据,以保证数据的可靠性和高可用性。
- Leader: Leader是指Kafka集群中的一个分区副本,它负责处理该分区的所有读写请求。Leader副本是唯一可以自主向分区写入数据的副本,它将写入的数据都会同步到所有的Folower副本中,以保证数据的可靠性和一致性。leader副本必须在leader节点中。
- Folower: Follower是指Kafka集群中的一个分区副本,Follower副本不能直接向分区写入数据,它只能从Leader副本中复制数据,并将数据同步到本地的副本中,以保证数据的可靠性和一致性。在Leader副本挂掉的时候Follower副本有机会被选举为新的leader副本从而保证分区的可用性。
2. 易混淆的概念
2.1 分区和副本
- 分区(Partition):Kafka中的每个主题(Topic)可以被划分为多个分区。每个分区内是一个有序的、不可变的消息序列,这些消息存储在Kafka集群的不同节点(broker)上。
- 副本(Replica):为了实现高可用性和数据冗余,每个分区的数据会被复制到多个节点上。每个分区的副本包括一个Leader副本和多个Follower副本。
2.2 Leader 节点和 Follower 节点
- Leader 节点:负责处理读写请求的分区主节点。
- Follower 节点:从 Leader副本 复制数据的分区从节点。
2.3 Leader 副本和 Follower 副本
- Leader副本:这是当前分区的主副本,负责处理所有的读写请求。Leader副本存储在被选为该分区Leader的节点上。
- Follower副本:这是从副本,从Leader副本复制数据,以保持数据的一致性和冗余。Follower副本存储在其他节点上。
2.4 Leader 副本只能存储在 Leader 节点上
- 集中处理:Leader节点负责处理所有的写请求和读请求,这样可以集中管理数据的更新和读取,简化了数据一致性管理。
- 减少延迟:由于读写请求直接由Leader节点处理,避免了在多个节点之间进行额外的网络通信,从而减少了延迟,提高了性能。
3. Kafka 的副本机制优势
Kafka 是支持多副本的,发生了一定的异常也可以保证系统正常运作,Kafka 的多副本机制大致有如下优势:
- 高可用性: 如果 Leader 副本所在的 Broker 宕机,Kafka 会自动从其它副本中选取一个新的 Leader,确保服务的持续性,具体选择规则我们后面会介绍。
- 容灾: 即使部分副本数据丢失,只要有一个副本是完整的,数据就不会丢失,简单来说就是多备份情况下数据丢失风险变小。
- 读性能提升: 默认情况下,虽然数据的多个副本可以分布在不同的 broker 上,但是Kafka都是Leader提供读写,如果特定业务需要,也可以让消费者从Follower上读数据,增加读的并发度。
4. 为用户的消息创建多副本
注意
分区的副本数量必须小于等于Broker的数量,比如只有1个Broker,却想为分区创建2个副本,会报错。
使用kafka-topics.sh脚本,并指定Topic名称、副本个数和分区数:
./kafka-topics.sh --create -bootstrap-server locahost:9092 --topic niugetest4 --partitions 2 --replication-factor 2如下图:
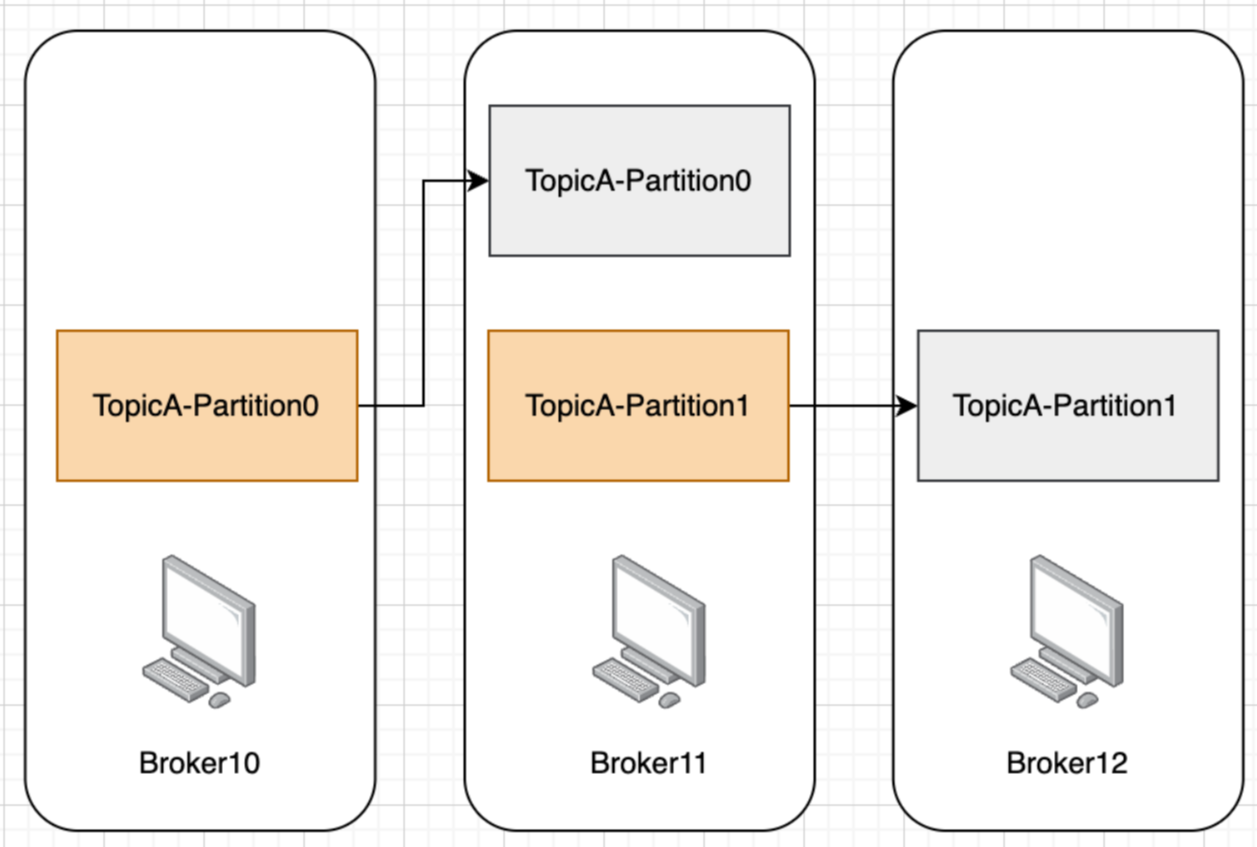
- 对于 TopicA 的 partition0 来说
- Broker10 是 Leader 节点,Broker10 的 TopicA-Partition0 是 Leader 副本
- Broker11 是 Follower 节点,Broker11 的 TopicA-Partition0 是 Follower 副本
- 数据持久化过程:不光写入Broker10上的Topic-A Partition0,还会最终同步到Broker11上的Topic-A Partition0
5. 为Kafka内部的Topic配置多副本
提示
待补充内容
二、多副本的写入机制
1. 写入机制
总结
数据是直接往Leader写入,写入之后Leader和Folower之间会进行同步,是否要等待同步完成取决于选择哪种写入策略(acks)。
- Kafka 会在诸多分区中选举一个分区作为主节点(Leader),它的副本作为Leader副本,负责接收生产者的消息并处理读写请求。
- 其他的副本是从副本,从Leader副本复制数据,保持只读。当主节点掉线后,有机会被选举成为新的主节点,去负责读写请求。Follower副本存储在其他节点上。
- 对于生产者来说,主节点是可见的,副节点是透明的。
2. 副本管理机制
一个分区会有多个副本,为了对这些副本更好的管理,Kafka 会对所有副本进行划分,对应不同的集合。
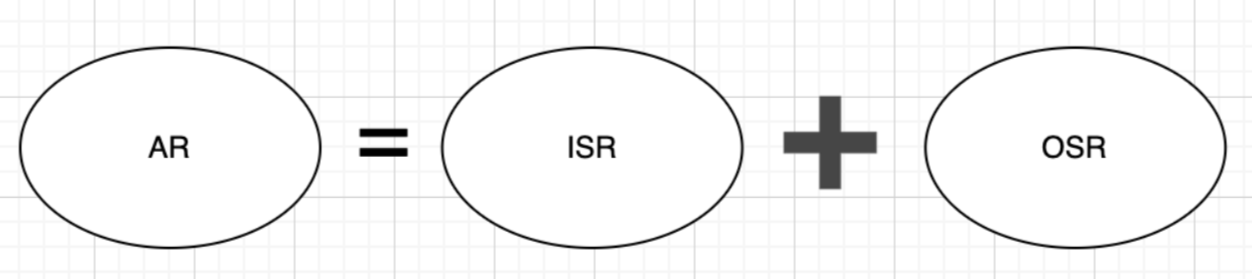
- AR 集合
- AR 是指分区的所有副本,包括 Leader 副本和 Follower 副本,也就是整体的集合。
- ISR 集合
- ISR 是指与 Leader 副本保持同步的副本集合,或者说是跟得上节奏的副本集合。
- ISR 中的副本与 Leader 副本保持同步,即它们已经复制了 Leader 副本中的所有数据,并且与 Leader 副本之间的数据差异不超过一定的阈值(Follower 副本能够落后 Leader 副本的最长时间间隔)。
- ISR 副本集合是动态变化的,不是一成不变的。除非开启了 Unclean 选举,否则只有处于 ISR 中的副本才有可能被选举为新的 Leader 副本,以保证分区的正常运行。
- OSR 集合
- OSR 是指与 Leader 副本不同步的副本集合,也就是跟不上节奏的副本
- OSR 中的副本与 Leader 副本之间的数据差异超过了一定的阈值,或者它们还没有复制 Leader 副本中的所有数据。除非开启了 Unclean 选举,否则 OSR 中的副本不能被选举为新的 Leader 副本。
简单来说:
3. ISR 的动态调整
每个Partition都会由Leader 动态维护一个与自己基本保持同步的ISR列表。
- 所谓动态维护,就是说如果一个Follower比一个Leader落后超过了给定阈值,默认是10s,则Leader将其从ISR中移除。
- 如果OSR列表内的Follower副本与Leader副本保持了同步,那么就将其添加到ISR列表当中。
4. ISR 为空,新 Leader 如何选举
可以通过配置参数 unclean.leader.election来决定是否从OSR中选举出leader:
- true: 允许 OSR 成为 Leader,但是 OSR 的消息较为滞后,可能会出现消息丢失的问题
- false: 坚决不能让那些OSR竞选Leader。这样做的后果是这个分区就不可用
三、副本间的同步机制
提示
待补充内容
四、副本间的同步机制 - 优化
提示
待补充内容