Kafka 实践应用经验
Kafka 实践应用经验
本文总结了Kafka在实际应用中的关键问题及解决方案,包括消息语义、消息可靠性、消息顺序性等重要主题。
一、消费消息的语义
1. 常见的消费语义
对于消息一般有如下几种消费模式:
- At most once 最多一次: 消息可能会丢失,但是绝对不会重复发送。适合对消息传递可靠性不高的场景,如日志记录。
- At least once 至少一次: 消息不会丢失,但是可能被重复发送处理,适合对消息传递可靠性有要求,但是能容忍消息重复的场景,如事件通知。
- Exactly once 精确一次: 消息不会丢失,也不会被重复发送,其适用于关键业务场景,需要严格保证消息处理一次且仅一次,如金融交易处理。
对于不同的业务需求,选择的消费语义不同。
2. 实现 精确一次 的困难
消息队列组件一般实现的都是至少一次语义,也就是至少能消费一次。
只要消息进入了 Kafka,是很容易实现至少一次语义的,但是需要考虑消息重复发送的可能性。
但在 kafka 中进一步实现精确一次消费是非常困难的,因为后端的任何一个环节都要考虑故障情况:
- 网络问题:网络延迟、中断....可能导致消息重复发送
- 并发处理:kafka支持并发消费,多个消费者可以同时消费一个topic,因此要有对应的同步机制和协调
- 消费者处理:消费者在消费消息的时候出现异常或者错误,导致消息处理失败,但是没有正确的处理这些异常情况,没有提交偏移量或者是一次失败了就不做了,没有重试机制,也可能导致消息重复消费
二、如何保证消息不丢失
1. 消息在什么环节可能发生丢失
- 生产阶段
- 存储阶段
- 消费阶段
保证消息不丢失,就要保证在这 3 个阶段的消息不丢失。

2. 生产阶段
结论
- Kafka本身是没有什么机制能保证生产一定成功的,需要有额外的确认机制才可以。
- 原因:这个环节是在数据进入消息队列之前,甚至可能因为某些原因都没发送过数据,所以不该由消息队列来保证,所以这个结论也不影响消息队列的可靠性。
在生产阶段要有重试和确认机制:
- 确认机制: 由Kafka 存储阶段 配合 producer的 acks 参数 实现,确保消息的可靠接收。
- 重试机制: 由Producer依据确认机制的反馈来实现,确保在发送失败时能够重新尝试发送消息。
3. 存储阶段
存储数据不丢失,也就是进去消息队列之后的数据,是持久的,Kafka这种消息队列,是非常可靠的,只要写入了队列,就不会丢消息。
这个依托于持久化存储:Kafka的消息确认机制依赖存储阶段
一旦消息被写入并确认(根据所选的确认级别),它就会被持久化存储到磁盘中。
这意味着即使系统发生故障或重启,已经确认的消息也不会丢失。它就可以被消费者至少消费一次。
存储阶段的ACK机制,有写入策略配置:
| Acks | 行为 | 可靠性 | 性能 |
|---|---|---|---|
| 0 | producer发送消息给broker后,不等待broker的确认消息。producer也就无法重试和确认信息是否发送成功 | 不可靠 | 最高 |
| 1(默认) | producer发送消息给broker后,等待leader节点的确认,但是不会等待所有follow的确认 | 相对可靠 | 比较高 |
| All | 只有所有的副本都成功写入消息后,producer才会收到确认 | 可靠 | 相对低一些 |
acks 参数的作用机制
- Producer发送消息:Producer将消息发送到Kafka集群中的目标分区的Leader节点。
- Leader节点处理消息:Leader节点接收到消息后,根据acks参数的配置,决定是否立即向Producer发送确认或者等待同步副本的确认。
- Follower节点同步数据:如果acks=all,Leader节点会等待所有同步副本(Follower节点)成功复制数据后,再向Producer发送确认。
一些疑问(已解决)
- acks是producer端配置的,发送消息到leader节点后,leader会根据acks参数决定是否回发确认以及何时回发确认
- acks参数是否是每次producer发送消息都要携带
- 要携带acks,那这个参数或者类似的参数等等....是携带在自定义的消息结构里面,也就是kafka 在应用层自定义的二进制协议
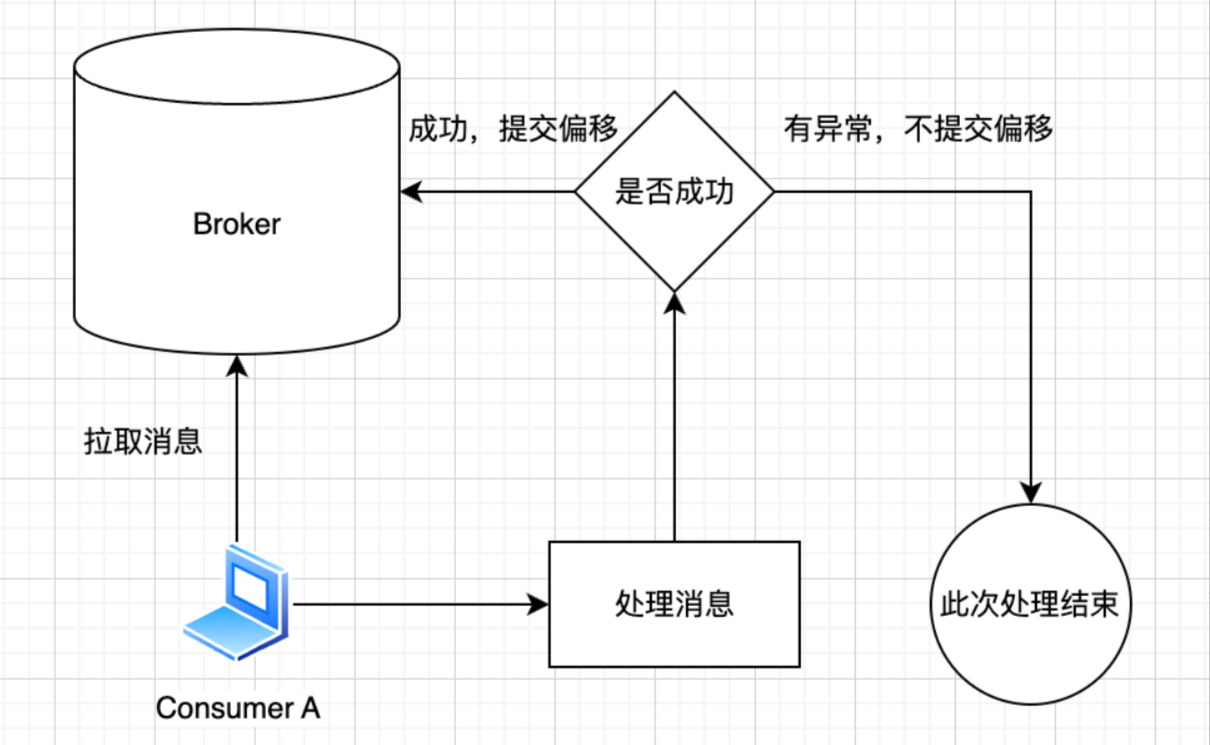
4. 消费阶段
Kafka提供了偏移量管理功能:Kafka消费者通过提交每个分区的偏移量来跟踪已经消费的消息。
即使消费者在处理消息时发生故障,重新启动后它仍然可以从最后一个提交的偏移量处继续消费,确保消息至少被处理一次。
上面是自动提交,也可用手动提交,由 consumer 业务代码自己控制提交时机,主动调用提交函数。
三、如何保证消息不重复
结论
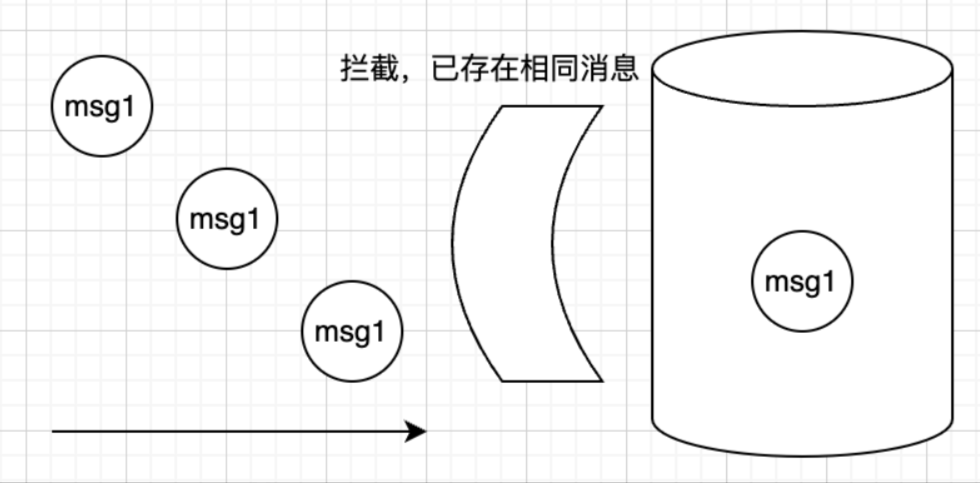
- 光靠消息队列是做不到不重复消费的,要消息队列配合业务逻辑配合完成。由于网络波动,基本上不可能让消息真的不重复,本质上不重复是手段,不重复产生影响才是目的。
1. 发生重复消费的场景
- 生产阶段: 发送时就重复了,比如网络波动,生产者重试发送,2次其实都发到了Broker
- 存储阶段: 在Kafka中存储的阶段,是不会重复的
- 消费阶段: 业务收到消息之后因为各种原因没有及时提交偏移,后面又拉到了相同消息
2. 常见防重实现思路
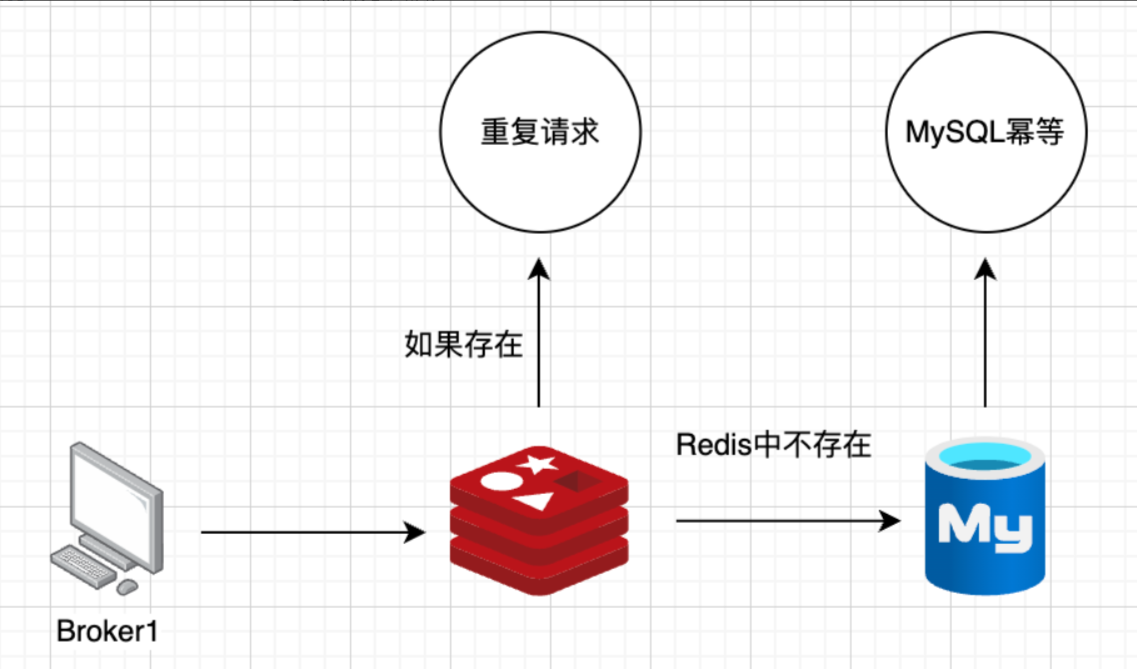
基于 redis:
- 唯一标识符: 为每个消息分配一个全局唯一的标识符(如UUID)
- Redis set: 将已消费的消息ID存储在Redis的Set数据结构中。每次消费消息前,检查该消息ID是否已存在于Set中
- 原子操作: 使用Redis的原子操作(如 SISMEMBER和 SADD)来检查和添加消息ID,确保操作的原子性
基于 mysql:
- 唯一约束: 在MySQL表中为消息ID创建一个唯一约束
- INSERT IGNORE: 使用 INSERT IGNORE或 ON DUPLICATE KEY UPDATE 语句来尝试插入消息记录。如果消息ID已存在,则忽略或更新该记录
- 事务: 在需要的情况下,使用事务来确保多个操作的原子性
3. 流量优化
如果业务用mysql做存储,可以参考上面的防重处理思路,基于此可以再做一些小优化:
如果重复请求过多,mysql 会无辜的多承担这部分的压力,如果再加一层 redis 做缓存限流,会好很多。
四、如何保证消息准确消费一次
1. 简单实现
消息不丢失 + 消息不重复 = 准确消费一次
五、如何保证消息有序
1. 什么场景需要有序
- 电商订单处理:
- 在电商系统中,用户的订单操作(下单、支付、取消等)需要按照时间顺序处理。比如,用户先下单再支付,如果消息顺序错乱,可能会导致支付消息先到而下单消息后到,从而引发逻辑错误。
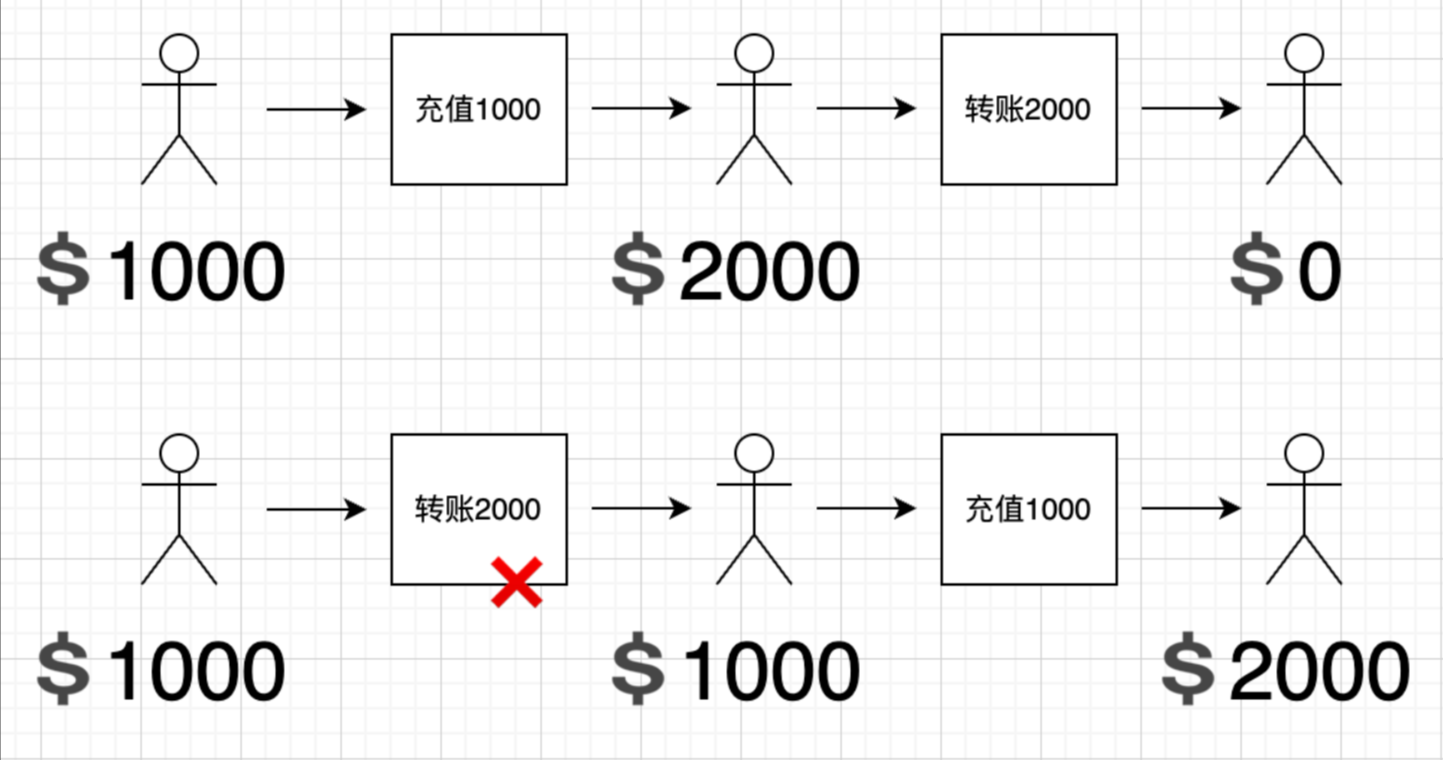
- 金融交易系统:
- 在股票交易或银行转账等金融系统中,交易操作必须严格按照时间顺序执行。任何顺序错乱可能导致账户数据不一致,甚至引发严重的金融风险。
- 任务调度:
- 在任务调度系统中,任务的执行顺序可能直接影响结果。例如,某些依赖性任务必须按特定顺序执行,顺序错乱可能导致依赖关系无法满足,任务失败。
2. 思路1:业务单分区
这是最简单的做法,就是根据业务确定分区,即每类业务自己一个分区,这样就可以实现业务消息有序。
具体而言,将业务所有消息都指定同一个分区Key,这样一来所有消息都会添加至同一个Partition,这样就达到了我们的目的。
潜在的不足之处:
在于这样做性能的扩展性就低了很多,当单个业务增长比较快,最后压力都给到了同一个Partition,无法发挥多Partition的优势,所以一般而言还会根据情况进一步地业务内分区。
3. 思路2:业务内多分区
提示
类似数据库分表
3.1 子业务分区
- 大业务分区:
同一个团队下,可能有不同的服务,比如:金融服务,消息服务等,假设他们都要传递消息给消息队列,显然可以金融服务一个分区,消息服务一个分区。
- 大业务 ----> 子业务:
- 金融服务分为:风控子业务一个分区,支付子业务一个分区
- 消息服务分为:短信通知分区,微信通知分区
3.2 客户分区
如果对于客户而言,数据是比较独立的,客户之间没什么交互,我们还可以按客户来分区。
比如消息是记录某个客户的减肥记录,里面包含了日期和减了多少斤,消费之后希望按投递的顺序记录进某个文件或数据库。
这种场景就是客户自己有序即可,客户不用关心别的客户减肥情况,也就是说客户之间不需要依赖。
符合这种场景的业务,就可以按客户来进行分区,比如最简单的,按用户id%100来分,这样就可以划出来100个分区,比如用户1001就用分区Key:user-mod-1,用户2002就用分区Key:user-mod-2
缺点:
这种方式有一个缺点,增减节点会对原有的路由分布会造成冲击。
比如原来9个分区,用户id是10,那算出来就是10 % 9 = 1 号分区。
假设增加一个分区,该用户就路由到 10 % 10= 0 号分区,也就是说,当节点增加或减少,原来的路由基本上是全乱了。
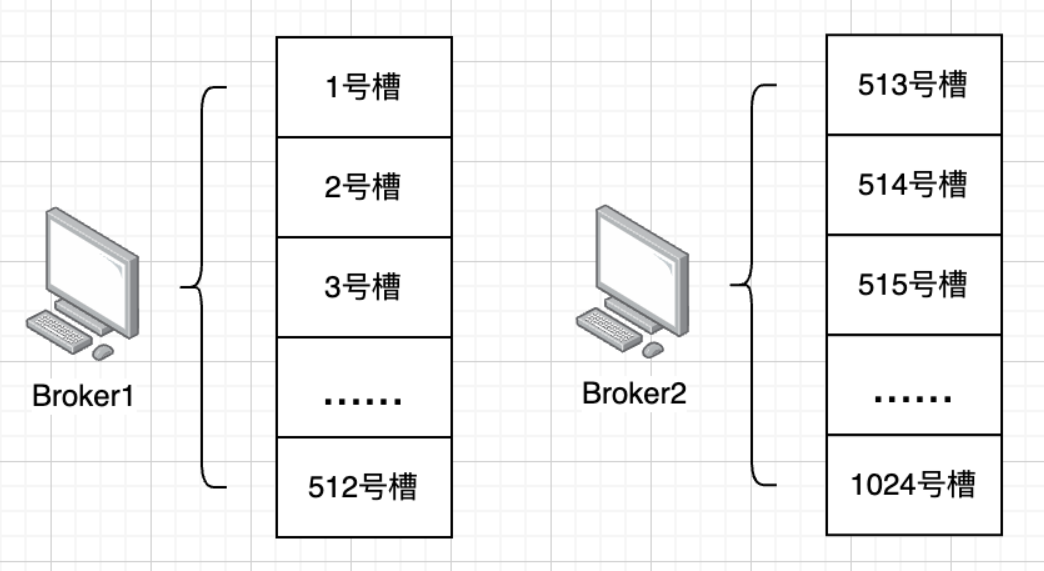
扩展思路:引入 hash 槽
每个节点负责一部分槽,用户id算出来在哪个槽,就去负载该槽的节点进行交互。
大致实现思路:
- 确定哈希函数 :
- 选择一个合适的哈希函数来计算每个客户的哈希值。常用的哈希函数包括 MD5、SHA-1 或者 CRC32 等。
- 定义哈希槽 :
- 确定哈希槽的数量(通常是一个固定的常量,比如 1024 或 2048)。这些哈希槽将用于将客户分配到不同的队列中。
- 计算哈希值并映射到哈希槽 :
- 使用哈希函数计算客户 ID 的哈希值。
- 将哈希值取模哈希槽的数量,得到一个哈希槽编号(hash_slot = hash(customer_id) % num_slots)。
- 分配队列 :
- 将每个哈希槽映射到一个特定的消息队列。这样,相同客户 ID 的消息总是会映射到同一个哈希槽,从而保证消息的有序性。
3.3 大小客户分区
提示
待补充内容