Redis压缩列表详解
2024年1月1日
压缩列表
压缩列表是什么
- 压缩列表:排列紧凑的列表
- 压缩列表在 redis 中有两种编码形式
- ziplist
- listpack:5.0 引入,直到 7.0 完全取代 ziplist,成为 ziplist 的进阶版本
解决什么问题
压缩列表是 list 的底层数据结构,压缩列表作为底层数据结构能提供紧凑型的数据存储方式,能节约内存(节省链表指针的开销),小数据量时遍历访问性能好(连续+缓存命中率高)
ziplist 整体结构
虽然 listpack,但是实际聊的比较多的还是 ziplist
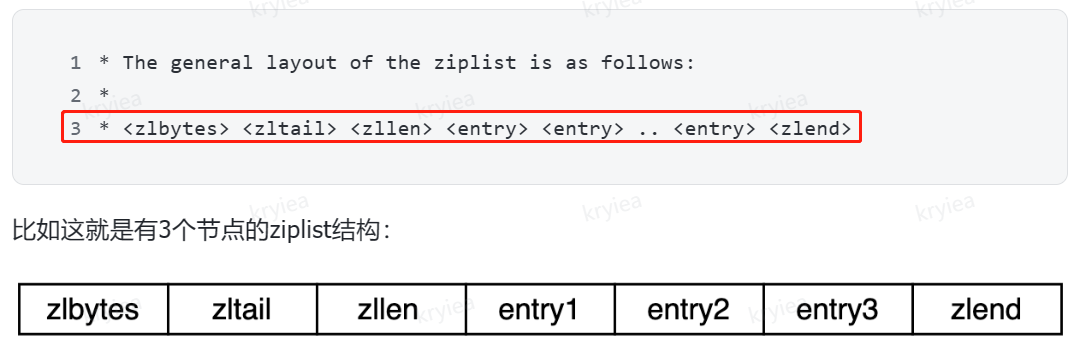
- zlbytes:表示该 ziplist 一共占了多少字节数,这个数字包含 zlbytes 本身占据的字节
- zltail:尾巴节点,相对于 ziplist 的开头(起始指针)而言偏移的字节数。
- 这个字段可以快速定位到尾部节点。
- 例如 zl 指向开头,需要获取尾巴节点,即 ziplist 最后一个 entry 节点,可以 zl + zltail
- 如果没有尾巴节点,就定位到 zlend,如空 ziplist
- zllen:表示有多少个数据节点,上图中,zllen = 3
- entry:表示压缩列表的数据节点
- zlend:一个特殊的 entry 节点,表示 ziplist 结束。
entry 节点结构
定义

- prevlen:表示上一个节点的数据长度。通过这个字段可以定位到上一个节点的起始地址
- 即当前地址 p-prevlen 可以跳到前一个节点的开头位置,实现从后往前的操作,所以压缩列表可以从后往前遍历
- 如果前一个节点 entry 的大小小于 254 字节,那么 prevlen 属性只需要用 1 字节长的空间来保存这个长度值。255 是特殊字符,被 zlend 使用
- 前一节点的长度大于等于 254 字节,那么 prevlen 属性需要 5 字节来保存这个长度值,注意 5 个字节中,第一个字节的 8bit 为 11111110,也就是 254,标志这是 5 个字节的 prelen 信息,剩下的 4 字节来表示大小
- encoding:编码类型。编码类型里还包含 entry 的长度信息,用于正向遍历
- entry-data:实际的数据
encoding
- encoding 字段是一个整形数据,其二进制编码由内容数据的类型和内容数据的字节长度两部分组成,根据内容类型有如下几种情况

- 如果是 string 类型,encoding 有两部分,一般是前几位表示类型,后几位表示长度。
- 如果是 int 类型,整体 1 字节编码,只是表示了类型,但没有大小,因为 int 的具体类型就自带了大小 int16、int32...不用要 encoding 特别标识
- encoding 的编码规则复杂,只要知道怎么去区分不同类型即可,不用去背具体编码。
- 解释一下表格最后一个 xxxx 为什么只有 13 个,全 1 不能用(zlend 用了),11111110 是 int64 也不能用
ziplist 查询数据
1. 查询 ziplist 数据总量
- 由于 ziplist 的 header 定义了记录节点数量的字段 zllen,通常可以在 O1 直接返回。
- 为什么是通常呢?
- 因为 zllen 是 2 个字节的,当 zllen 大于 65534,就存不下了,zllen 变成 0, 此时真实的 zllen 需要重新遍历得到
注意
- list 使用 ziplist 编码的条件之一是数据对象的数量小于 512,超过就会使用 linkedlist 编码
- 而 ziplist 这个数据结构,本身的限制是可以存 65534 个数据(也不算限制,存超了就需要重新遍历浪费 On,而不是直接 O1 返回)
- 简而言之,list 底层使用了 ziplist 这个底层数据结构,并且自己设定了一个限制,数据量小于 512
2. 查询指定数据的节点
需要遍历这个压缩列表,平均 On,所以查找复杂度是比较高的
3. 更新数据
数据节点 entry 往后移
- ziplist 支持在头尾插入数据,但是平均操作时间确是 On 不是 O1,因为在头部增加一个节点会导致后面的节点都往后移动
连锁更新
这里有图文讲解Redis 数据结构
- entry 后移不叫连锁更新!
- 连锁更新的情况:
- 增加一个大于 254 字节的节点到头部,可能会导致后续大量entry 的 prevlen 需要更新。
- 比如:原本每个 entry 中的 prevlen 都是 1 字节,而且每个 entry 的总字节数都接近 254。挺好的,无事发生。
- 突然加了一个大于 254 字节的数据到头部,导致后一个 entry 的 prevlen 原本 1 字节太小了,需要重新分配大小为 5 字节,从 1 变 5,导致这个 entry 的总字节数大于 254,下一个 entry 的 prevlen 又要 1 变 5。
- 小林的图文解释的很好。
- 这种现象叫连锁更新,时间复杂度是 On^2
- 连锁更新会带来性能问题,虽然实际很少遇到,但是 ziplist 最大的问题还是连锁更新导致性能不稳定
listpack 优化
目的:解决连锁更新
ziplist 连锁更新原因分析
- list 是双端访问结构,而 ziplist 需要支持 list 双端访问的特性,在 entry 增加了 prevlen 字段记录上一个节点的长度,使其能够从后往前遍历。
- 连锁更新就是 prevlen 需要字节从 1 变 5 导致的
entry 的结构
对症下药
需要一种不记录 prevlen,并且还可以找到上一节点的起始位置的办法
listpack。
listpack 节点定义

- encoding-type:编码类型
- element-data:数据内容
- element-tot-len:存储整个节点除了它自身之外的长度。就是 type+data
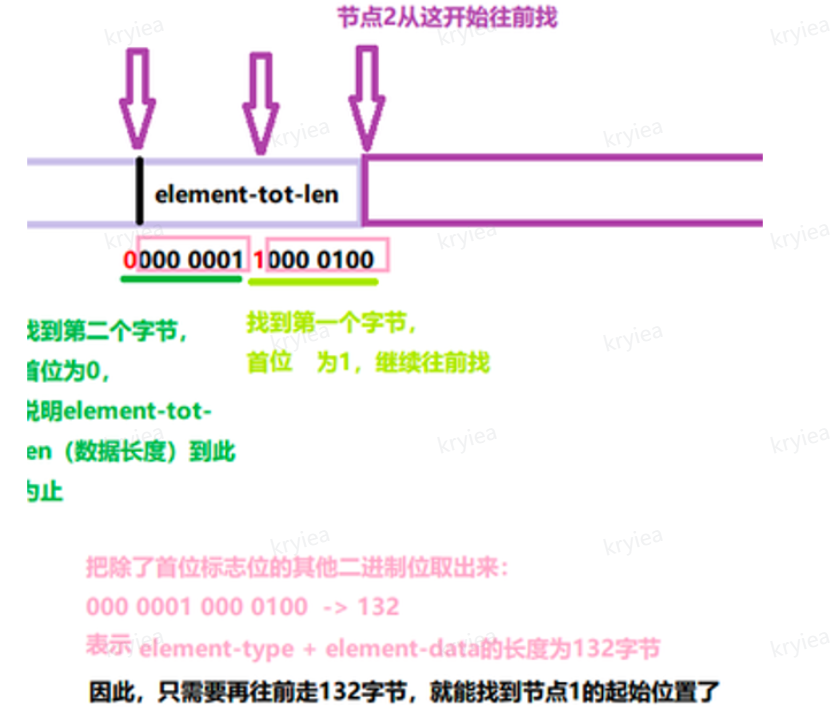
element-tot-len
- tot-len 所占用的每个字节的第一个 bit 用于标识是否结束。
- 0 结束,1 结束。剩下的 7 个 bit 用来存储数据大小
- 当我们需要查找当前元素的上一个元素,可以从 tot-len 从后往前依次查找每一个字节,找到上一个 entry 的 tot-len 结束标识,就可以算出上一个节点的受位置
- 例子:上一个 tot-len 为 00000001 1000010,每个字节第一个 bit 标志是否结束。
- 从后往前依次查找,把有效的 7 位拿出来,拼接在一起:0000001 000010 = 132 字节
- 说明再往前走 132 字节就到了节点起始位置
listpack 结构设计
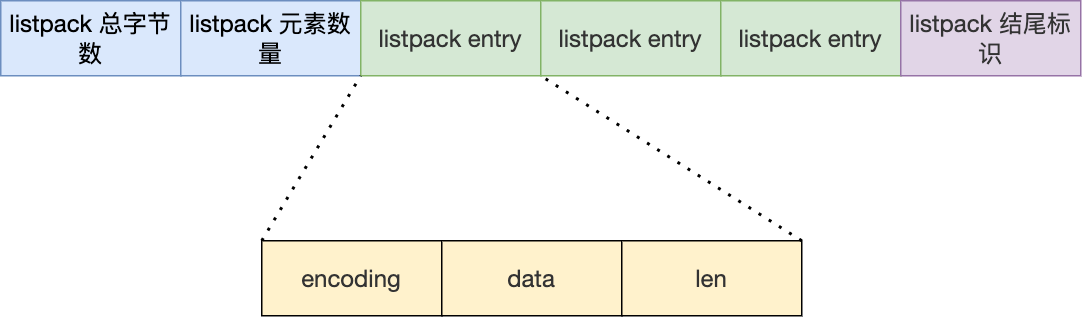
- listpack entry 的三个字段就是上面的
总结
- listpack 和 ziplist 都叫压缩列表,前者是后者的进阶版,解决了连锁更新带来的性能瓶颈
- 在结构上没太大的区别,用 element-tot-len 取代了导致连锁更新的 prevlen