Redis LRU内存淘汰算法详解
2024年1月1日
内存淘汰算法-LRU
标准 LRU
LRU 是一个流行的资源淘汰算法
是什么
最近最久未使用,即记录每个 key 的最近访问时间,维护一个访问时间数据
redis 使用标准的 LRU 会有什么问题
为所有数据维护一个顺序列表,实际就是做一个双向链表,如果 redis 数据稍微多些,这个链表就成本就很大
redis 的近似 LRU
概述
- 在 LRU 模式中,redisObject 对象中 lru 字段存储的是 key 被访问时,redis 的时钟 server.lrulock
- 当 key 被访问时,redis 会更新这个 key 的 lru 字段
- 但是,redis 为了保证核心单线程服务性能,缓存了 Unix 操作系统时钟,默认每 100ms 更新一次,缓存的值时 Unix 时间戳取模 2^24
近似 LRU
- 近似 lru 算法在现有的数据结构基础上采用随机取样的方式来淘汰元素,当内存不足,就执行一次近似 lru
- 具体步骤:
- 随机采用 n 个 key,默认 5 个
- 根据时间戳淘汰掉最旧的 key
- 淘汰后还是内存不足,继续采样淘汰
采样范围
- allkeys:从所有 key 中随机采样
- volatile:从有过期时间的 key 随机采样
对应:allkeys-lru 和 volatile-lru
淘汰池优化
近似 lru 的一些问题
近似 lru 优点在于节约了内存,但缺点就是它不是一完整的 lru,随机采样得到的结果,其实不是全局真正的最久未访问,数据量大的时候更加
redis3.0 对近似 lru 进行了一些优化
- 新算法会维护一个大小为 16 (不是固定的,会动态调整)的候选池,池中的数据根据空闲时间长短进行排序
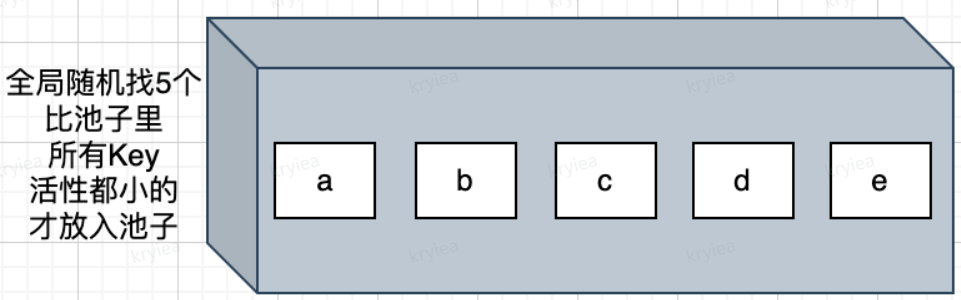
- 第一次随机选取的 key 都会放入池中,然后淘汰最久未访问的。 比如选了 5 个,淘汰 1 个,池子还剩 4 个
- 随后每次随机选取的 key,只有活性比池子里活性最小的 key 还小时,才会放入池中
- 池子满了之后每次放一个 key 进,满之前符合的都放进
- 当池子满了,如果有新的 key 需要放入,就会将池子中活性最低(这里的活性低就是空闲时间长)的 key 淘汰
- 新的 key 要放入的意思:随机选取的 n 个采样里面活性最低的与池中活性最低的比较,谁更低谁被淘汰,没被淘汰的放入池子
空闲时间的计算
idle = object.lru - server.lrulock
淘汰池的结构
Redis的淘汰池是一个字典结构,而不是链表。
字典中的每个键值对都包含一个指向对象的指针,而不是相邻节点的指针。
因此,在遍历淘汰池时,Redis需要使用哈希表算法来查找大于当前最大可用内存的键。
