Redis跳表实现详解
2024年1月1日
跳表
是什么
- 跳表是有序集合 zset 底层数据结构,也是 zset 的灵魂所在。
- 跳表本质还是链表

- 虽然链表结构简单清晰,但是查询某个节点的效率比较低,为了调高查找性能,引入了跳表。
- 跳表在链表基础上,给链表增加了多级索引,通过索引可以一次实现多个节点的跳跃,调高性能
跳表的结构
结构示意图
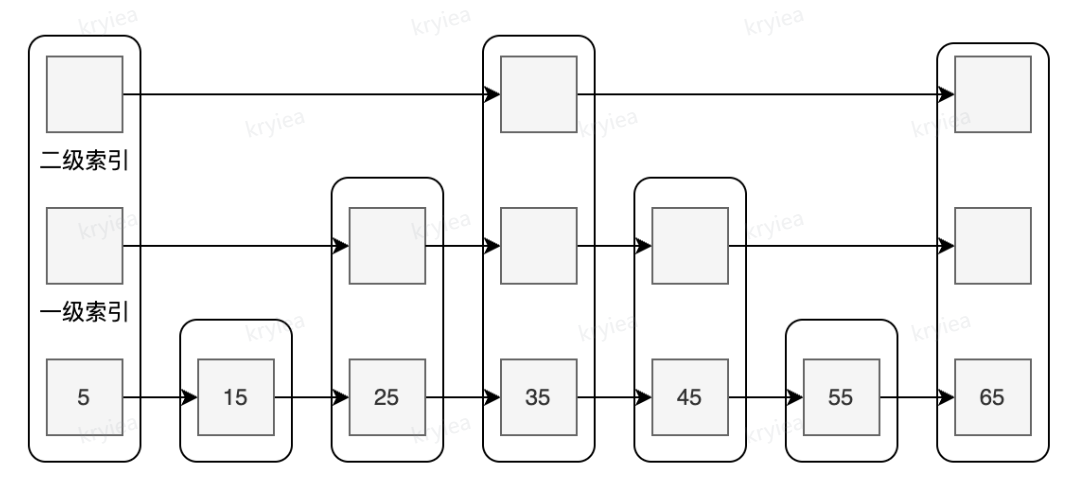
- 图上的某些节点不是只有一层。比如 35,就有三层
- 理论上,层次越高平均步长越大,并不是和上图一样绝对均衡的,节点的层高是概率随机的
或者这样画
结构的好处
场景 1:查找分数为 35 的数据
- 如果是只有原始链表,需要走 4 步
- 二级索引走一步
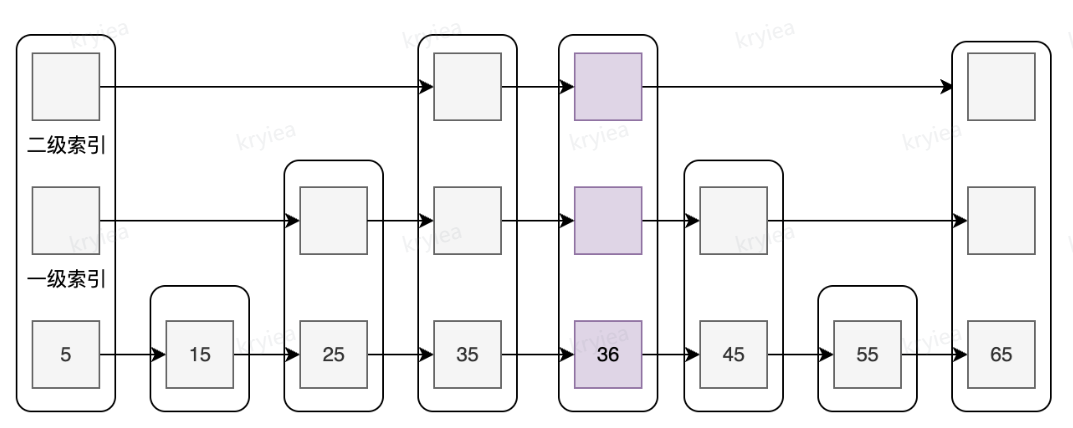
场景 2:插入 score 为 36 的数据
- 先定位到第一个比 score 大的位置,这里是 45,定位方式和查询类似
- 然后构造一个新节点,假设节点层高随机到 3(随机算法决定的)
- 补齐各层链表
标准的跳表的限制
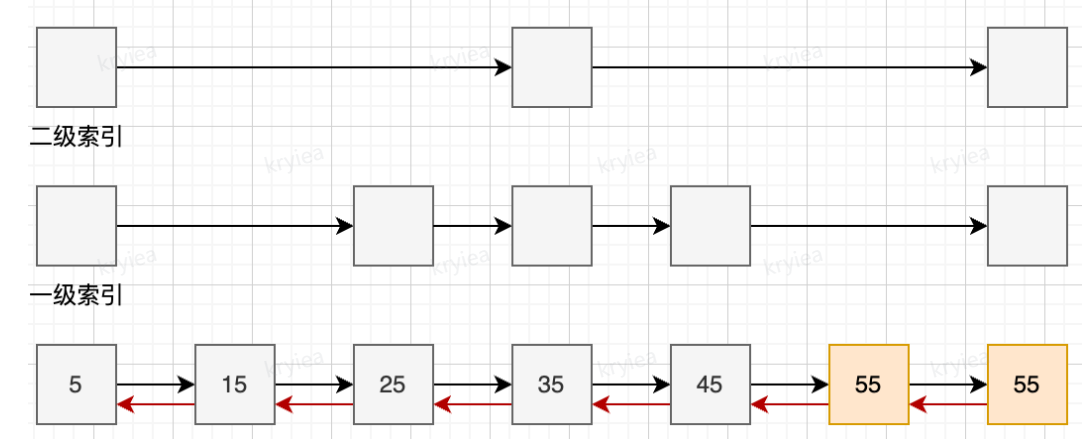
- score 不能重复
- 只有向前指针,没有回退指针
⛔在 reids 中,跳表是用来支持有序集合的,所以 redis 对跳表做了一些优化:
- score 可以重复
- 增加回退指针
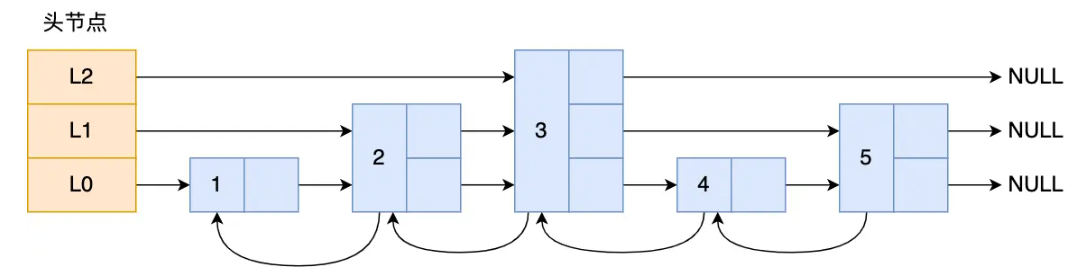
redis 的跳表实现
结构图
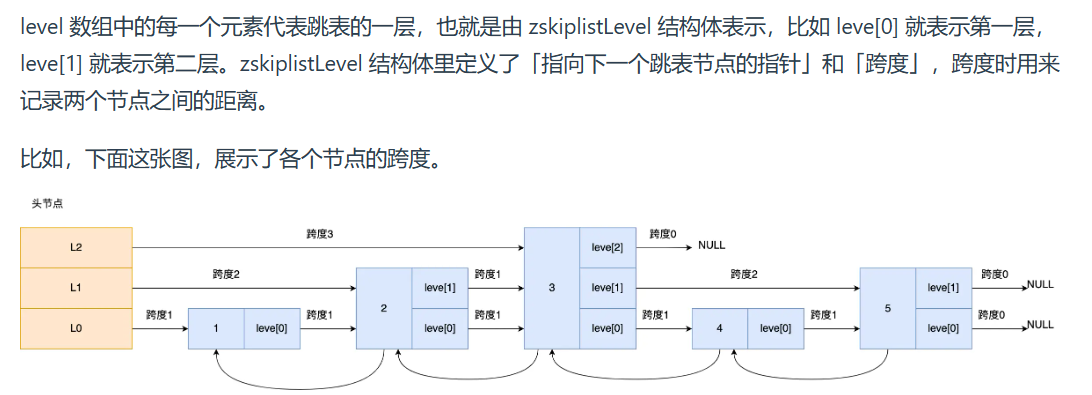
下面的更准确。
节点源码

- ele:sds 结构,用来存储数据
- score:节点的分数,浮点型数据。节点排列是从小到大
- backwaid:指向上一个节点的回退指针。支持从表尾向表头遍历,也就是ZREVRANGE命令
- level:是 zskiplistLevel 结构体数组,有两个字段:
- forward:指向该层下一个能跳到的节点
- span:记录距离下一个节点的步数
- 结构体数组:表示每个节点都可能是多层结构
跳表结构体

redis 跳表单个节点有几层
层次的决定,需要比较随机才能在各个场景表现出较为平均的性能,这里 redis 使用概率均衡的死了来决定新插入节点的层数:
- redis 跳表决定每一个节点,是否能增加一层的概率为 25%,而最大层数限制在 redis5.0 是 64 层,7.0 是 32 层