Redis单线程高性能原理解析
2024年1月1日
redis 单线程为什么这么快
快的 4 点原因
- 基于内存设计,内存的读写速度对比磁盘和固态都快,有更高的吞吐量和低延迟。
- 单线程,因为执行本身不是瓶颈。对比多线程,从投入产生来看,引入多线程要付出更大的时间复杂度:上下文切换,同步机制的开销等等成本很高。事实也证明单纯性的 redis 已经很高效。瓶颈通常在网络 IO。
- IO 多路复用
- 高效的底层数据结构
redis 单线程
redis 使用单线程,能达到每秒数万级别的处理能力
- redis 大部分操作在内存上完成,内存操作本身快
- redis 选择了很多高效的数据结构,并做了很多优化,比如 ziplist、hash、跳表....
- 有时候一种对象底层有几种实现以对应不同的场景
- redis 采用了多路复用机制,使其在网络 IO 操作中,能并发处理大量的客户端请求,实现高吞吐量
IO 可能存在的问题
一个单线程在一次完整的处理中, 会有哪些地方拖慢整个流程
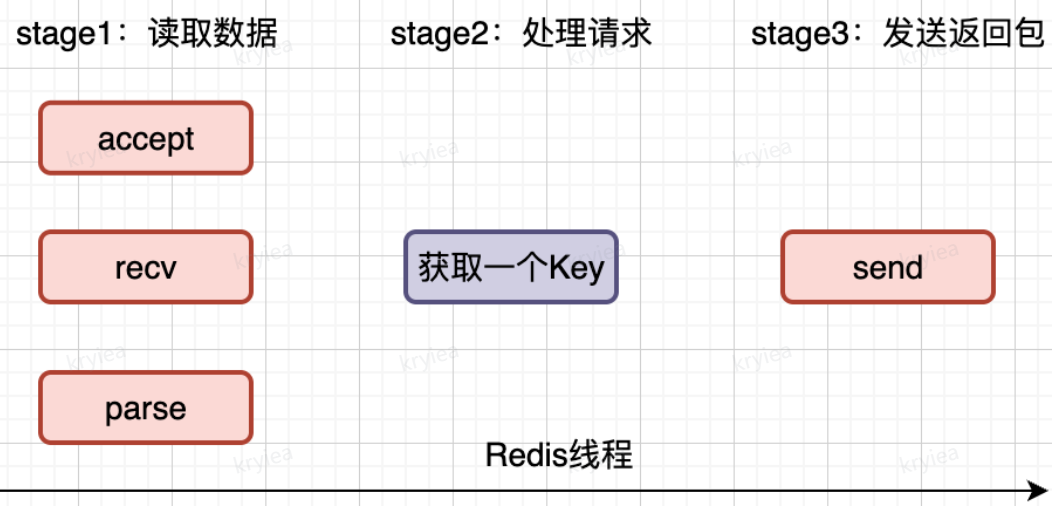
redis 服务端在启动时,以及 bind 了端口,并且 listen 操作监听客户端请求,此时客户端就可以发起连接请求
- 客户端 get 请求到来,使用 accept 建立连接
- 调用 recv 从套接字中读取请求
- 解析客户端发送请求,拿到参数
- 处理请求,这里是 get,redis 通过 key 获取对应的数据
- 最后将数据通过 send 发送给客户端
哪些流程会拖沓
套接字默认是阻塞模式的,可能发生在两个地方
- accept 时:accept 建立时间过长
- recv 时:客户端一直都没有发送数据
怎么解决:IO 多路复用
当有 IO 操作触发的时候,就会产生通知,收到通知,再去通知对应的事件,针对 IO 多路复用,reids 做了一层包装,叫 Reactor 模型
Reactor
本质就是监听各种事件,当事件发生,将事件分发给不同的处理器
这样就不会阻塞在一个操作上,IO 多路复用让 redis 单线程也有了较大的并发度(不是并行)