Redis哈希表底层结构详解
2024年1月1日
hashtable底层结构
概述
- 可以理解成目录,要翻看内容可以直接通过目录找到页数,翻过去看
- hashtable 扮演者类似目录这样一个快速索引角色
结构
代码定义

结构图
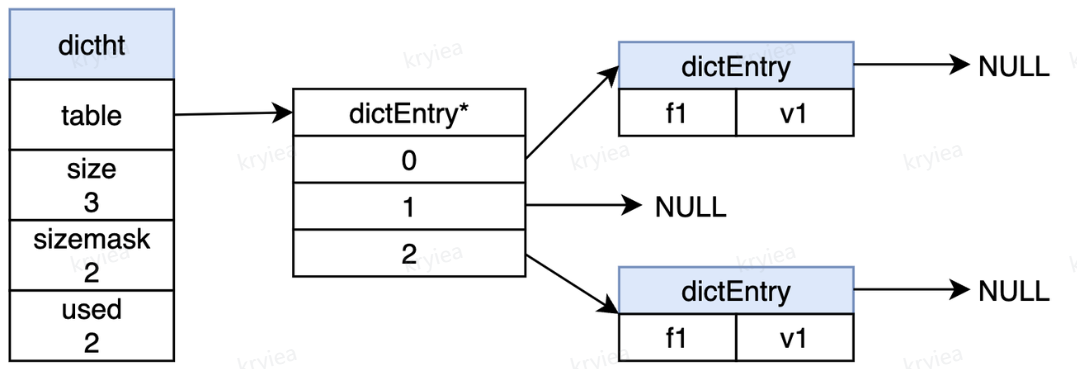
- 最外层是一个 dictht,字段如下
- *table:指向实际 hash 存储。存储看成一个数组
- size:哈希大小。实际就是 dictEntry 有多少元素空间
- sizemask:哈希表大小的掩码表示,总是等于 size-1.这个属性和哈希值一起决定一个键一个被放在 table 数组的哪个索引上面,规则是:Index = hash&sizemask
- used:表示已经使用的节点数量
hash 表渐进式扩容
reids 把 dictht 再封装了一层:dict

结构图
- dict 结构里 ht[2] 包含两个 dictht 结构,也就是 2 个 hashtable
- dictEntry 是链表结构,用拉链法解决 hash 冲突,用的是头插法
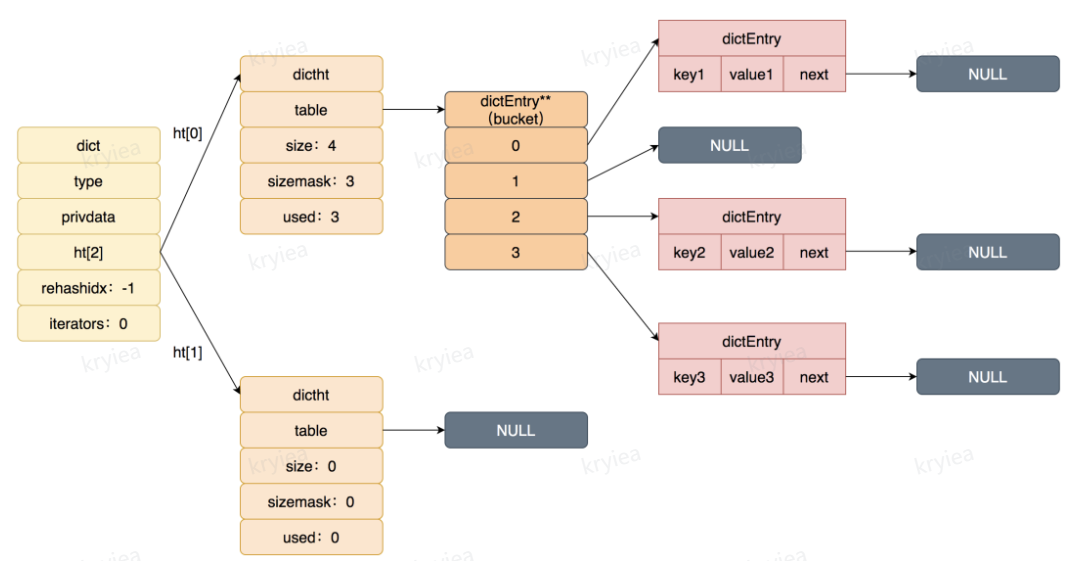
扩容:渐进式!
- 实际平常使用的是一个 hashtable,在触发扩容之后,就会两个 hashtable 同时使用
- 扩容过程:往字典添加元素,发现需要扩容会进行 rehash
- 先为新 hash 表 ht[1] 分配空间,新表大小为第一个大于等于原表 2 倍 used 的 2 次方幂 🌰原表的 used = 500,2 倍就是 1000,那大于 1000 的 2 次方幂则为 1024
- 扩容后,同时拥有两个 hash 表 ht[0]、ht[1]。
- 将字典的偏移索引 rehashidx 从静默状态 -1,设置为 0,表示 rehash 工作正式开始
- 工作流程

- 迁移 ht[0] 的数据到 ht[1]
- 在 rehash 期间,每次对字典执行增删改查,程序会顺带迁移当前 rehashidx 在 ht[0] 上对应的数据,并更新偏移索引。(只有被删改查的数据才会别迁移,不然一直不动)
- 与此同时,部分情况周期函数也会进行迁移
- 随着字典操作不断,最终在某个时间点上,ht[0] 的所有数据会被 rehash 到 ht[1] 上
- 此时将 ht[1] 和 ht[0] 的指针互换,同时将偏移索引的值设为-1,表示 rehash 已经完成
dictRehash 函数

- 可以看到,如果 rehashidx 刚好在一个已经删除的空位置,是会继续往下找,但是有上限 n*10
- n 是传进来的参数,调用时实际为 1,则最多往后找 10 个,防止因为碰到连续的空位置导致主线程操作被阻塞
- 每次迁移一个函数,rehash 都会检查一下是否完成整个迁移
总结
核心是:操作时顺带迁移
扩容时机
负载因子表示目前 redis hashtable 的负载情况
- 设负载因子为 k
- k = ht[0].used / ht[0].size
- k 是会大于 1 的,因为是拉链法处理扩容,且 used 是表示 dictEntry** 的使用情况
何时扩容
- 负载因子大于等于 1:说明空间非常紧张
- 新数据实在链表上叠加的(拉链法),越来越多数据无法在 O1 时间复杂度上找到,需要遍历一次链表
- 如果此时服务器没有执行 BGSAVE 或 BGREWRITEAOF 这两个命令 (复制命令)
- 就发生扩容
- 负载因子大于 5:说明 hashtable 不堪重负
- 现在即使有复制命令在执行,也会进行 rehash 扩容
缩容
渐进式缩容:看负载因子 k
- k 小于 0.1,即负载率小于 10%,就会进行缩容
- 新表大小为第一个大于等于原表 used 的 2 次方幂
- 如果有BGSAVE 或 BGREWRITEAOF 这两个复制命令,缩容不会进行
总结
hashtable 是面试热点。。